分布式系统知识大纲
本文将简单介绍分布式系统涉及的技术点,可以作为一个学习大纲。后续还需要深入的学习其中的知识点。
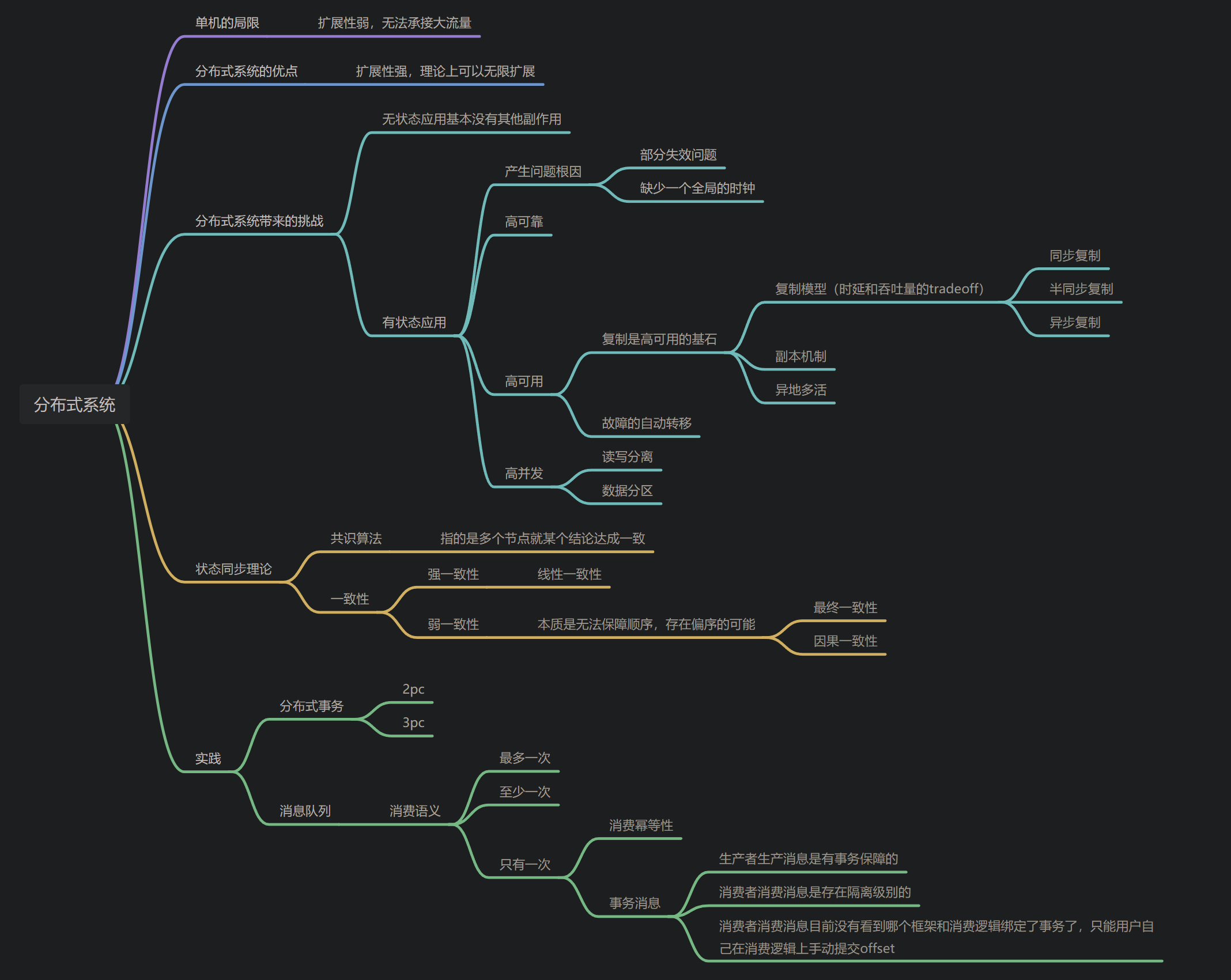
背景
互联网的繁荣发展给每个人的生活带来了翻天覆地的变化。而这些对于提供互联网服务的公司也带来的大流量的压力,传统的单机承接不了这么大的流量压力,哪怕是升级机器配置也有承受的上限!
而 分布式系统 就是来解决这个问题的,它可以理解为多个普通计算机节点联合起来一起工作,对客户端而言,就像只有一台单机在工作一般,理论上分布式系统是可以无限扩展的。
优点
- 弹性高:分布式系统的节点数量可以动态增删
- 成本低:多个普通节点可以完成一个高配置机器能完成的任务
缺点
极大的提高了运维复杂度。假如一台机器故障概率是 1%,那么 10 台机器可能导致故障概率是 (1-(1-0.01)^10)= 9.5%。在分布式环境下,机器出故障的概率会大大增加。
理论基础
CAP 定理
这个定理是分布式系统理论上的一个基本准则,指的是以下三种特性只能保障两个:
C:一致性,指的是多个节点对外提供一致的数据。(这样描述不够准确,我们可以理解为客户端同一时刻访问分布式系统的任意一个节点,获取到的数据是一样的)
A:可用性,指的是系统中任意一个节点发生问题时,数据和其他节点不一致,是否选择让它还对外提供服务。如果继续服务,则说明系统选择了可用性。
P:网络分区,只要节点是通过网络进行交互的,则一定会发生网络分区,如果发生分区,就不对外提供服务,那么这个系统将极其不可靠。
因此,我们一般会根据场景选择 CP 或者 AP 系统。
不过,这里的一致性指的是 强一致性,在实际应用中,实现它代价太大了,于是理论上的 CAP 定理,到工程实践上就变成了 BASE 理论。
basically available:基本可用,允许系统丧失部分可用性
soft state:软状态,允许系统的数据存在中间状态,也就是允许客户端访问到过期数据
eventually consistent:最终一致性,系统最后会达到一致的状态,不保证实时达到一致性。
有状态应用
上面的定理的应用对象就是 有状态应用,指的是应用中存在数据,如果数据完全在第三方数据源上,应用无状态,那么这个分布式系统无论怎么折腾都可以,节点可以任意故障。
一般来说,我们希望业务应用能做到是无状态应用,然而有时候不可避免会保留本地缓存,如何保持这份本地缓存的一致性也是一个挑战,一个行之有效的方法是设置缓存的随机失效时间
共识算法
共识指的是分布式系统多个节点就某一个提议达成了一致。
这么说有点抽象,要注意的是共识算法并不等同于实现了强一致性,它还存在一些限制。比如一个实现典型 raft 算法的分布式系统,只能通过主节点进行读写操作,其他节点只能当作副本。
不过在现实中很多场景问题都可以等价为共识问题:
- 原子事务提交
- 全序广播
- 分布式锁和租约
- 选主
一致性
一致性在分布式系统是一个很“晦涩”的话题。
最理想的环境下,我们希望整个分布式系统可以当作一个单机来看待,就没有什么一致性的问题了。也可以说整个系统做到了“强一致性”。
然而现实是,做到强一致性代价太大了,就有了各种妥协。分布式系统有两个固有的缺陷,第一个是前文提及的节点随时会失效;另一个就是和一致性相关的缺少一个 全序时钟,每个节点的时钟不能保证一致。那么客户端访问不同节点的操作就无法通过时间戳确定先后顺序。
在一些场景下,两个操作之间有依赖关系。于是衍生出“顺序一致性”,“最终一致性”,“因果一致性”等多种一致性概念。
分布式事务
和本地事务不同,分布式事务是多个数据源共同参与的,目的也是追求数据逻辑的一致性。而这一点和共识算法有一点点相似的地方,两者都是为了做到数据的一致性。而且原理上都有一点用到了 2pc 的思想。
2pc 核心在于有一个预提交的中间状态,这个中间状态让各个节点可以感知其他节点的情况,进行回滚或者提交!当然,它必然是中心化的系统,需要一个事务协调节点。这就带来了单点问题,就有更为复杂的 3pc 方案
“三高”追求
三高,是每一个架构设计所追求的!
高可靠 & 高可用
高可靠和高可用是类似概念,指的是一个服务能连续提供服务的时长,也就是服务很稳定,很可靠,另一个层面来说,就算遇到问题,也能保证关键数据不丢失!
一般来说会涉及很多方面的问题,如硬件,软件,网络,运维等。而解决方案似乎出奇的一致:复制。由此衍生的名词有,主从复制,副本机制,异地多活,故障转移等。
高性能
高性能指的就是系统可以承受多大的流量,一般来说节点越多,性能越好。然而对于有状态应用,还有诸多限制。关于这一方面也有很多名词:读写分离,集群机制,哨兵机制,数据分区等
实践
服务注册和发现
这个点本不应该放入分布式系统中来讲的,这个更多的是微服务的概念,微服务之间采用 RPC 进行通信。需要服务注册和发现的过程。
分布式消息队列
消息队列作为一个典型案例来讲解。它涉及了数据分区,副本机制,主从切换等常见分布式数据系统遇到的问题。
数据同步到多副本的过程还存在一个复制模型的选择问题:
- 同步复制:所有副本 ack 再返回
- 半同步复制:部分数量的副本 ack 后返回
- 异步复制:不等待副本 ack 直接返回
而对于消息队列本身,还有一个消费模型的语义选择: - 至多一次消费:每个消息最多消费一次
- 至少一次消费:每个消息至少消费一次
- 只消费一次:每个消息会且只会消费一次,这需要依靠消息幂等性和消息事务来实现。不同消息队列产品实现的方式不一致
参考资料
共识、线性一致性、顺序一致性、最终一致性、强一致性讲解_最终一致性和强一致性-CSDN博客
多角度理解一致性 | 李乾坤的博客 (qiankunli.github.io)
Replication(下):事务,一致性与共识 (qq.com)
Replication(上):常见的复制模型&分布式系统的挑战 (qq.com)